THE SILENT HEIST: HOW LLM DISTILLATION ATTACKS WORK AND WHY THEY ARE A THREAT TO AI'S FUTURE
DeepSeek, Moonshot AI, and MiniMax stole Claude's capabilities via distillation attacks. Learn how knowledge distillation works and how these attacks are carried out.

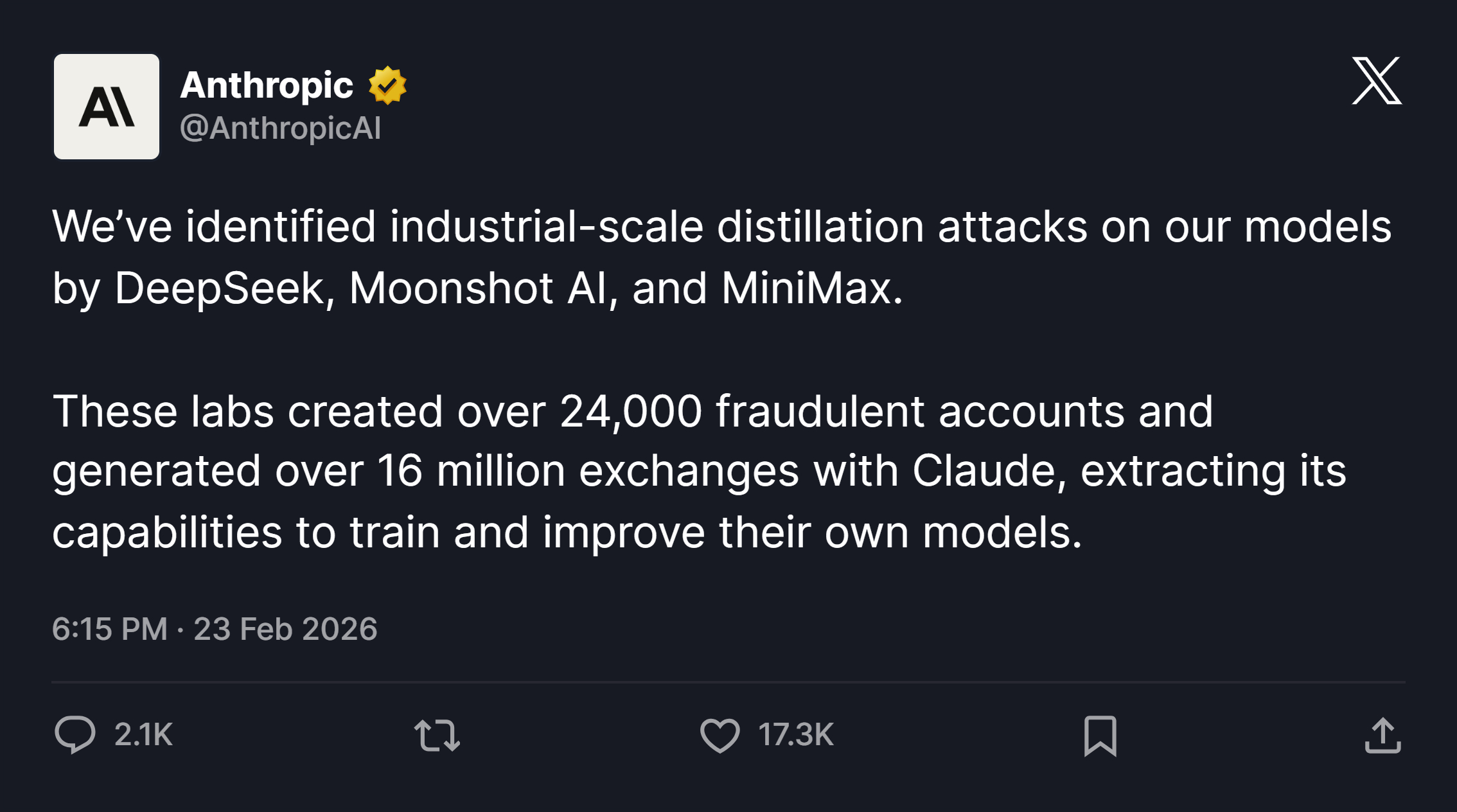
Anthropic dropped a bombshell: three major AI laboratories -- DeepSeek, Moonshot AI, and MiniMax -- had been running industrial-scale campaigns to illicitly steal Claude's capabilities. They created over 24,000 fraudulent accounts, generated more than 16 million exchanges with Claude, and used the extracted data to train and improve their own competing models. The technique they exploited is called knowledge distillation -- a method that is legitimate, widely used, and now increasingly weaponized.
This post breaks down exactly how distillation works, how it gets turned into an attack, and what the AI industry is doing about it.
WHAT IS KNOWLEDGE DISTILLATION?
Knowledge distillation is a model compression technique where a large, capable model -- called the teacher -- transfers its knowledge to a smaller, cheaper model called the student. The goal is to get the student model to perform close to the teacher's level while being far cheaper to deploy and run.
Think of it as an apprenticeship: the student doesn't learn from raw data from scratch. It learns by watching how the teacher answers, absorbing not just the right answers but the confidence patterns behind them.
THE TEACHER-STUDENT MECHANISM
When a teacher model like GPT-4 or Claude makes a prediction, it doesn't just output a single answer. It generates a probability distribution across all possible tokens -- what researchers call soft targets or soft labels. For example, if asked "What's the capital of France?", the teacher might assign 95% probability to "Paris", 3% to "Lyon", 1% to "Marseille", and so on.
These soft probability distributions are far richer than just the label "Paris." They encode the teacher's internal uncertainty, conceptual groupings, and latent knowledge about language relationships. A student model trained on these soft targets learns much more nuanced representations than one trained purely on hard labels (right or wrong).
THE CORE MATH
The student is trained by minimizing two combined losses:
KL Divergence Loss -- measures how different the student's probability distribution is from the teacher's soft targets.
Cross-Entropy Loss -- standard classification loss against the true labels.
The combined distillation loss is:
L = alpha L_KL(p_T^tau, p_S^tau) + (1 - alpha) L_CE(y, p_S)
where tau is the temperature parameter. A higher temperature "softens" the probability distribution, exposing more of the teacher's latent reasoning structure to the student.
TYPES OF LEGITIMATE DISTILLATION
Type | What is Transferred | Used For |
|---|---|---|
Response Distillation | Final output tokens / answers | Building smaller task-specific models |
Feature Distillation | Intermediate layer activations | Aligning architectures of diff sizes |
Chain-of-Thought | Step-by-step reasoning traces | Teaching reasoning to smaller models |
Preference Distillation | Teacher-student output quality ranks | Improving alignment and calibration |
Frontier labs do this all the time -- legitimately. GPT-4o mini is effectively a distilled version of GPT-4. Anthropic itself creates smaller Claude versions by distilling its flagship models. It is a normal part of the AI development lifecycle.
WHEN DISTILLATION BECOMES AN ATTACK
Distillation turns into an attack when a third party -- without permission -- systematically queries a proprietary model's API, collects outputs at scale, and trains a competing model on those responses. The economic incentive is enormous.
Training a frontier model from scratch costs billions of dollars. DeepSeek claims it trained its R1 model for around $6 million -- widely suspected to be because it leveraged distillation from U.S. models rather than training from raw data alone. The same technique that makes model compression cost-effective becomes a capability theft mechanism when applied to someone else's model.
THE DISTILLATION ATTACK PLAYBOOK
Anthropic's investigation revealed a consistent, sophisticated playbook across all three labs.
Step 1 -- Fraudulent Account Infrastructure (Hydra Clusters)
Attackers don't access the API directly under their own identity. They use commercial proxy services that resell API access at scale and build what Anthropic calls "hydra cluster" architectures -- sprawling networks of fraudulent accounts spread across direct API access and third-party cloud platforms.
The "hydra" metaphor is apt: when one account is banned, a new one automatically replaces it. In one case, a single proxy network managed more than 20,000 fraudulent accounts simultaneously, mixing distillation traffic with unrelated customer requests to make detection harder.
Step 2 -- Carefully Crafted Capability-Extraction Prompts
Once access is secured, labs send large volumes of deliberately structured prompts designed to extract specific, high-value capabilities. A single prompt like this may look completely innocuous:
"You are an expert data analyst combining statistical rigor with deep domain knowledge. Your goal is to deliver data-driven insights grounded in real data and supported by complete and transparent reasoning."
But when variations of this prompt arrive tens of thousands of times across hundreds of coordinated accounts -- all targeting the same narrow capability cluster such as coding, agentic reasoning, or tool use -- the pattern becomes unmistakable. Volume concentration, repetitive structure, and content that maps directly onto what is most valuable for AI training are the hallmarks of a distillation attack.
Step 3 -- Chain-of-Thought Trace Harvesting
The most valuable extraction technique is chain-of-thought elicitation. DeepSeek's prompts specifically asked Claude to "imagine and articulate the internal reasoning behind a completed response and write it out step by step" -- effectively generating chain-of-thought training data at scale.
This is particularly dangerous because chain-of-thought traces transmit far more than the surface answer. They encode latent reasoning patterns, problem decomposition strategies, and even alignment-related behaviors. A student model trained on CoT traces can learn to reason, not just mimic.
THE THREE CAMPAIGNS ANTHROPIC UNCOVERED
DeepSeek -- 150,000+ Exchanges
DeepSeek ran synchronized traffic across accounts with identical patterns, shared payment methods, and coordinated timing -- a classic load-balancing approach to maximize throughput while evading detection. Most notably, they used Claude to generate censorship-safe alternatives to politically sensitive queries. Anthropic was able to trace the accounts back to specific researchers at DeepSeek through request metadata.
Moonshot AI (Kimi) -- 3.4 Million+ Exchanges
Moonshot employed hundreds of fraudulent accounts spanning multiple access pathways, using varied account types to make coordinated detection harder. The attribution came through request metadata matching public profiles of senior Moonshot staff. In a later phase, they pivoted to a more targeted approach: attempting to reconstruct Claude's reasoning traces from scratch.
MiniMax -- 13 Million+ Exchanges
MiniMax ran the largest campaign by far, targeting agentic coding and tool use orchestration. Anthropic caught this campaign while it was still active -- before MiniMax released the model it was training. Most tellingly: when Anthropic released a new model version during MiniMax's active campaign, MiniMax pivoted within 24 hours, redirecting nearly half their traffic to capture capabilities from the latest system.
WHY DISTILLATION ATTACKS ARE MORE DANGEROUS THAN THEY LOOK
Missing Safety Guardrails
Claude and other frontier models are built with extensive safety systems to prevent misuse -- for example, refusing to help synthesize bioweapons or assist with malicious cyber operations. When a model is built via illicit distillation, those safety constraints are not automatically inherited. The capability gets cloned; the guardrails do not. The result is a frontier-capable model with the safety properties of an unaligned system.
Undermining Export Controls
The U.S. has implemented chip export controls specifically to prevent adversarial nations from training frontier AI models. Distillation attacks circumvent that strategy at the software layer. The capability gap that export controls are meant to preserve gets closed anyway through stolen model outputs.
The Competitive Inversion Problem
When Chinese labs make rapid AI progress, the surface-level interpretation is that export controls aren't working. But if that progress is substantially powered by distillation from American models, then export controls are working exactly as intended -- the adversary's progress is dependent on continued access to U.S. AI outputs, not on independent innovation. Anthropic's disclosure reframes the entire export control debate.
HOW DEFENSES WORK
Anthropic and other frontier labs are building multi-layered responses:
Behavioral Fingerprinting and Classifiers: Automated detection systems that identify distillation attack patterns in API traffic, including detection of chain-of-thought elicitation used to construct reasoning training data.
Coordinated Account Detection: Tools for identifying correlated behavior across large numbers of accounts -- shared payment methods, synchronized timing, identical prompt structures.
Chain-of-Thought Summarization: Anthropic summarizes long reasoning traces before serving them, reducing the amount of explicit CoT information available for extraction while preserving answer quality.
Watermarking: Embedding invisible statistical watermarks in model outputs so that if those outputs appear in a competing model's training data, it can be proven cryptographically.
Access Control Hardening: Strengthening identity verification for educational accounts, security research programs, and startup accounts -- the pathways most commonly exploited to set up fraudulent API access.
Intelligence Sharing: Sharing technical indicators (IP clusters, request metadata patterns) with other AI labs, cloud providers, and government authorities.
Model-Level Countermeasures: Developing API and model-level safeguards that degrade the usefulness of model outputs specifically for distillation training, without affecting the experience of legitimate users.
OpenAI has similarly begun training its models to avoid revealing reasoning paths, using classifiers to detect and mask chain-of-thought leakage before it reaches the API response.
THE BIGGER PICTURE
Distillation attacks represent a new category of AI security threat that sits at the intersection of intellectual property law, national security, and AI safety. They are technically sophisticated, economically motivated, and structurally difficult to stop -- because the underlying technique (querying an API and collecting outputs) is identical to normal, legitimate usage.
The difference between a user and an attacker isn't the action -- it's the intent, scale, and systematic structure behind that action. Detecting that boundary at API scale, in real-time, across millions of requests, is a genuinely hard problem. The fact that Anthropic caught MiniMax mid-campaign before their model launched suggests the industry is getting better at it -- but the race between extractors and defenders is far from over.
The window to establish norms, technical defenses, and legal frameworks around distillation attacks is narrow and closing fast. As Anthropic put it: addressing this will require rapid, coordinated action among industry players, policymakers, and the global AI community.